OSD Home
Resolving memory conflicts created by multitasking
If you have multitasking, you have multiple tasks in memory.
Will they all occupy the same address? How will you prevent conflicts?
- Static tasks; linked into the kernel when the kernel
is built, so each task gets a unique address 'automatically'.
- Task executables use a relocatable format. The kernel loads the
task into whatever memory is available, then performs something
like the final step of linking (relocation).
- Tasks use position-independent code (PIC), so they can run
at any memory address, without relocation or address translation.
- Address translation prevents memory conflicts.
Address translation
This means the virtual addresses generated by a program are
different from the physical addresses that go onto the address
bus; to the memory chips. The translation of virtual addresses to
physical addresses is performed by special hardware inside the CPU
called a memory management unit (MMU).
Address translation can be used for the kernel as well as the tasks.
This lets you link the kernel to run at a specific address, but
load the kernel anywhere in memory.
Besides address translation, the MMU usually provides memory
protection. Ranges of memory can be made to cause a page
fault or general protection fault by any combination of
- writing to the memory range,
- accessing the memory range in any way (read, write, execute),
- access to the memory range by code running at user privilege (ring 3).
x86 segment-based address translation
Linear address translation. Every byte in the address
space has the same virtual-to-physical conversion value. If you
want different v-to-p values, you need multiple segments
(and therefore far pointers).
The v-to-p value is simply the segment base address.
Example: a kernel compiled to run at virtual address C0000000h
(3 gig) but loaded to physical address 00100000h (1 meg). The
kernel will run properly if the segment base addresses are set
to 40100000h:
| virtual address generated by kernel code
| +
| conversion value (i.e. segment base address)
| =
| physical address
|
| C0000000h (3 gig)
| +
| 40100000h
| =
| 00100000h (1 meg)
|
Advantages of segmentation over paging:
- Speed. Reloading segment registers to change address spaces
is much faster than switching page tables.
- Segment descriptor tables consume less memory than page tables.
- x86 page table entries do not have an 'Executable' bit.
With segmentation, you can make a region of memory executable
(code) or not (data).
- Segment size can be byte-granular (size 1 byte to 1Meg in units
of 1 byte); pages are always page-granular (size 4K to 4Gig in units
of 4K). Segmentation lets you make the segment as large as necessary,
with no excess (there is no internal fragmentation).
The only freely-available C compiler that supports both 32-bit code
and multiple segments is Watcom C. See
http://www.openwatcom.org
Page-based address translation
Non-linear address translation. Each 4K page can have a
different v-to-p value.
The v-to-p values come from a system of page tables,
created and stored in memory.
Advantages of paging over segmentation:
- Page-based address translation turns non-contiguous physical
addresses into contiguous virtual addresses (the external
fragmentation of free memory does not matter).
- Many CPUs support paging, only a few support segmentation
- Some things that are easy to do with paging but hard to do
with segmentation unless you have multiple segments:
- Efficient support for sparse address spaces. You
can have large 'holes' in the virtual address space, like the
hole between the top of the heap and the top of the stack.
- Shared memory between tasks.
- Some things are easier to do with paging because x86 page
fault, unlike general protection fault, stores the faulting
address in register CR2:
- Demand-loading. No page of memory is allocated for
a task until the task actually accesses the memory. This
prevents a heavy load on the CPU when a task first starts up.
It also conserves RAM.
- Memory-mapped files. This lets you read and write
a file by reading and writing memory locations.
- Swapping. If RAM runs low, the kernel can copy pages
that haven't been accessed recently to a swapfile on the disk,
to free RAM for more active tasks.
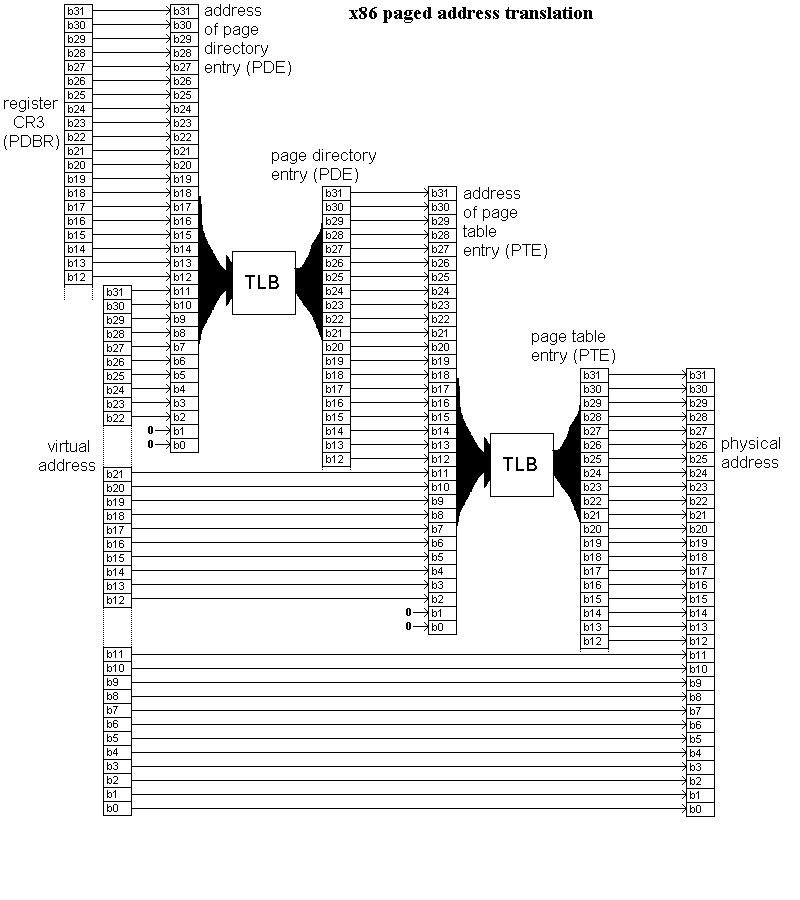
Translation of virtual addresses to physical
addresses, using 2-level paging as found on x86. In this image, note:
- Page directories and page tables start in memory on page (4K) boundaries.
- The bottom 12 bits of the virtual address are not translated.
- Page directory and page table entries are cached in the CPU,
in a special cache called a translation lookaside buffer (TLB).
This is also known as an address translation cache (ATC). Were
it not for the TLB/ATC, two additional memory reads would be needed
for each memory access.
Paged address spaces
- Each task has its own page directory, and therefore, its own paged
address space.
- Each address space is typically divided into three regions:
identity-mapped memory at the bottom, task virtual memory, and
kernel virtual memory. The kernel virtual memory is usually at the top
of the address space.
- The task virtual memory is private to each task; the identity-mapped
and kernel virtual memory are shared among all tasks.
- In mature kernels, no page of memory should be accessible with more
than one type of address (identity-mapped, task virtual, or kernel
virtual). This preserves as much as possible of the 4 Gbyte address space
for the tasks. It does, however, lead to situations where memory is
inaccessible to the kernel unless the kernel changes address spaces or
creates temporary memory mappings.
Identity-mapped memory
For identity-mapped memory, the page tables are programmed so that no
address translation is performed (virtual addresses = physical).
These pages are still subject to page-based protection. Kernel memory
must be identity-mapped while paging is initialized. From 'Intel
Architecture Software Developer's Manual':
17.22.3. Enabling and Disabling Paging
Paging is enabled and disabled by loading a value into
control register CR0 that modifies the PG flag. For
backward and forward compatibility with all Intel
Architecture processors, Intel recommends that the
following operations be performed when enabling or
disabling paging:
1. Execute a MOV CR0,REG instruction to either set
(enable paging) or clear (disable paging) the PG flag.
2. Execute a near JMP instruction.
The sequence bounded by the MOV and JMP instructions
should be identity mapped (that is, the instructions
should reside on a page whose linear and physical
addresses are identical).
The page table entries used to identity-map kernel memory can be
deleted once paging and virtual addresses are enabled.
If you want to run 32-bit code in the BIOS ROMs (e.g. PCI BIOS), the
ROMs must also be identity-mapped.
Many kernel data structures are <= 4K in size. Since memory fragmentation
is not an issue for these, they may be stored in identity-mapped memory
or kernel virtual memory, whichever is more convenient.
Inaccessible memory
The task virtual memory for a task other than the current task can not
be accessed unless:
- the memory for the other task is shared with the current task
- the memory is (temporarily) shared with the kernel
- the kernel switches address spaces.
Switching address spaces causes the TLB to be reloaded. This is slow, and
should be avoided unless the task in the new address space is the next
task to run. (In other words, switching address spaces should be done
only by the scheduler.)
DMA restrictions on virtual memory
Since DMA operates directly on memory, it doesn't know about virtual
addresses. There are several ways to handle this:
- Scatter-gather. The DMA controller has registers that contain
information for converting virtual addreses to physical. ISA DMA does
not perform scatter-gather, but many PCI devices do.
- Software scatter-gather. DMA transfers are restricted to 4K chunks.
Conversion between virtual and physical addresses is done in software,
by the kernel.
- The kernel memory allocator can be modified to supply memory that is
physically contiguous e.g. kmalloc(nnn, GFP_DMA) under Linux.
Each page of memory in such a region has the same virtual-to-physical
conversion value, so DMA can be done in a single operation.
Code snippets
Links
A good introduction to paging, with nice graphics:
http://www.embedded.com/98/9806fe2.htm
Linux VM commentary:
http://www.csn.ul.ie/~mel/projects/vm/. Also discusses
the buddy algorithm and slab allocator.
Tim Robinson's virtual memory tutorials:
http://www.gaat.freeserve.co.uk/tutes
VM systems of popular OSes:
Virtual memory tutorial:
http://www.cne.gmu.edu/modules/vm/submap.html
Alexei Frounze's paging tutorial:
http://alexfru.chat.ru/epm.html#pagetrans
Chris Giese's paging demo:
http://my.execpc.com/~geezer/os/paging.zip
TO DO
- Demand-loading.
- Shared memory between tasks, for IPC or DLLs. Shared copy-on-
write (COW) memory, for fork(). Other shared memory
(e.g. framebuffer in task data segment)
- Swapping. Choosing pages to swap out. LRU, NRU, clock algorithm,
working sets.
- Memory-mapped files.
- When must you invalidate the TLB? two ways to do it:
- 386 method (reload CR3); flushes entire TLB
- 486+ method (INVLPG instruction); flushes one TLB entry
Which of these two methods is faster and when?
Improved (tagged) TLBs on non-x86 CPUs.
- P6+ CPUs allow "global" pages. The mappings for these are not
flushed from the TLB when CR3 is reloaded (only by INVLPG).
See bit b7 of register CR4.
- Paging code in detail: pseudocode or walk-through of page fault
handler, state diagram or life-cycle of a page.
- Virtual memory layout of common OSes: Windows NT, Windows 9x,
Linux, BSD, other?
- Accessing page tables with virtual addresses: make one entry in
the page directory point to the page directory itself, then
addresses that go through this entry let you treat the page
tables as pages
- Kernel's view of memory
- Task memory layout in detail
- Intel documents use the term 'linear address' where these
documents use the term 'virtual address'. I think the word
'linear' is confusing because it's used for about a million
other things.
{kind=link}